As a customer on a VPS (virtual private server), the cpu load depends on many resource decisions that are outside of your control. Some of the resource restrictions might be synchronized due to everyone running a cronjob at the same time, or just a stochastic pile-up.
This spikiness of use means that the average load over any interval can yield false positives in alerts. Instead of using the first moment (average), we can use the third (skew) to tell us when load is a persistent problem over some interval.
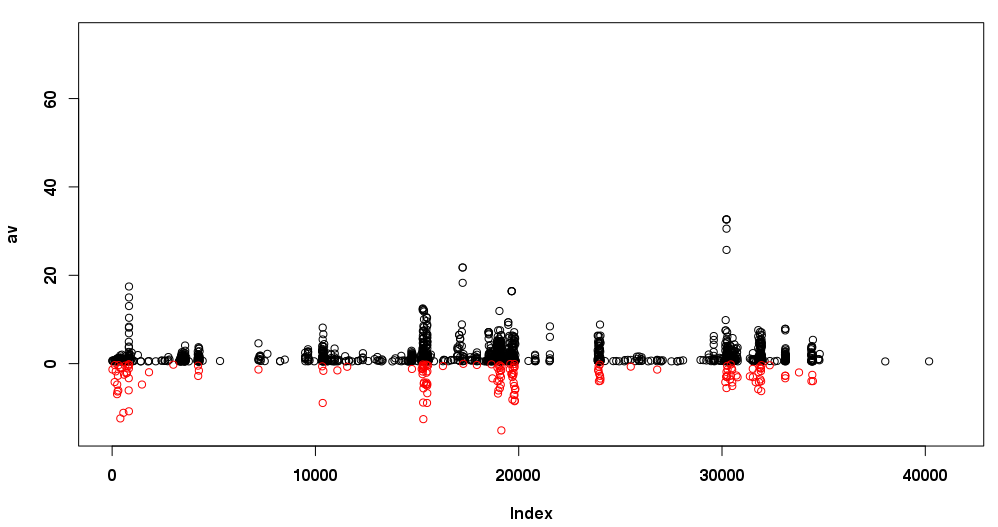
The red is the skew (times 10 to make the graph more obvious) and the load average is black (I also didn't graph any load below 0.5 which is why there's a skew with no corresponding load average above it). The clumpings of black where there is no red show the spiky load which would have triggered a false positive. The data came from CollectdStatsGSL which I use to cheaply transform collectd load data into its moments.